-
[Database] - Cardinality / Cluster IndexCS/DB 2022. 10. 4. 00:29
Index를 설정할 때 주로 사용하는 Where 조건이나, FK를 Index를 효율적인라는 것은 알 수 있다.
'Student' 라는 Table에 'ID' , 'Name' , 'Phone' 이라는 Column이 존재한다고 가정해봅시다.
Index는 'ID' , 'Phone'으로 2개의 Column이 복합적으로 잡혀있다고 하여 봅시다.
당연히 2개를 사용하여 Select하는 것이 제일 좋습니다.
그 다음에는 둘 중 하나라도 Index를 타게 하는것이 좋습니다.
하지만, 그렇다고 하여서 Index 많이 설정하면 좋을까요?
그렇지 않습니다.
Index는 DB Memory를 사용하여 Table형태로 별도로 저장됨으로 Index가 많아지면 결국 저장공간과 개수도 비례하여 증가합니다.
Index를 설정
어떤 Column Index를 설정하는게 좋을까요?
1. Cardinality
- Column이 가지고 있는 중복 정도
- 'ID'는 학생 마다 부여 받은 Unique한 값임으로 Cardinality가 좋다
- 'Name' 은 동명이인이 있을 수 있음으로 'ID'보다는 Cardinality가 낮다고 할 수 있다.
2. Selectivily
- 특정 Data를 얼마나 잘 선택 할 수 있는지 지표
- 'Student' Table에서 'ID' , 'Name' , 'Sex' 라는 Column이 있다라고 합니다.
- 'ID'는 학생마다 Unique 하며 Name은 동명이인이 2명씩 있고, 성별은 남자5명 여성5명으로 나뉜다고 하여 봅시다.
- 특정 값 Row / 테이블의 총 Row * 100
- 값들의 평균 Row / 테이블의 총 Row * 100
- 'ID' = 1/10*100 = 10%
- 'Name' = 2/10*100 = 20%
- 'Name' = 5/10*100 = 50%
3. 활용도
Column이 실제 작업에서 얼마나 자주 활용되는지 대한 값
쿼리 Select , Procedure , Service에서 자주 사용되는 Column
4. 중복도
중복이 낮을 수록 Index 설정에 좋은 Column 입니다.
Index
- 하나의 Column에 Primary key를 지정하면 자동으로 Clustered Index가 생성된다.
- Clustered Index가 없다면, Unique 제약 조건이 있는 Table을 만들면 DB engine은 자동으로 Non-Clustered Index를 만든다.
- PK를 지정하는 Column에 강제로 non-Cluster index 지정이 가능하다.
- 기존 Table에 이미 PK가 있다면, non-Cluster index 지정
- 제약 조건 없이 테이블 생성시에 Index를 만들 수 없으며, Index가 자동 생성되기 위한 열의 제약 조건은 Primary Key또는 Unique 뿐이다.
Clustered Index
- Clustered Index는 테이블의 데이터를 지정된 컬럼에 대해 물리적으로 데이터를 재배열한다.
Index를 생성할 때는 데이터 페이지 전체를 다시 정렬 - 데이터가 테이블에 삽입되는 순서에 상관없이 Index로 생성되어 있는 컬럼을 기준으로 정렬되어 삽입된다.
- Index Page를 키값과 데이터 페이지 번호로 구성하고, 검색하고자하는 데이터의 키 값으로 페이지 번호를 검색하여 데이터를 찾는다.
- Clustered Index는 테이블 당 한개씩만 존재 가능하다.
- 테이블에 데이터가 많이 저장된 상태에서 ALTER를 통해 Clustered Index를 추가한다면, 많은 데이터를 정렬해야 해서 많은 리소스를 차지하게 된다. -> 사용자의 이용시간이 많을 때 변경하면 안된다.
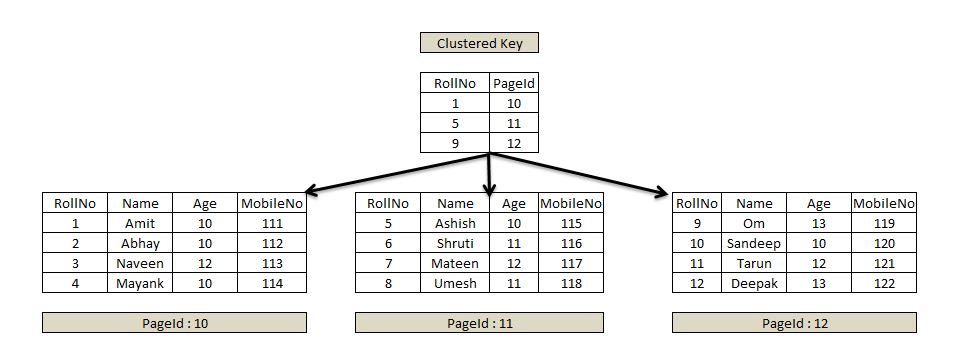
동작 원리
- Clustered Index는 Root Page + Leaf Page 로 구성된다.
- Leaf Page = Data 값이다.
- Physical 적으로도 정렬되어 있어 Non-clustered index보다 더 빠르다.
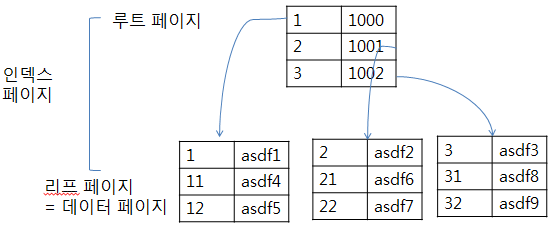
Non-Clustered Index
- Physical적으로 물리적 Data를 정렬하지 않고 Data Page를 구성하여 Mapping한다.
- Table Data는 그대로 두고 지정된 Column에 대해 정렬된 Index를 만든다.
- Clustered Index에 비해Select 속도는 떨어지지만, DML(Insert,Update,Delete)는 더 빠르다.
- 여러 개 존재 가능하다.

동작원리
- Data Page를 건드리지 않고, 별도의 장소에 Index Page를 Create
- Index Page는 Key로 Sort하여 RID로 구성된다.
- Leaf Page에 Index로 구성한 뒤 RID를 생성한다.
- RID는 데이터가 위치하는 장소
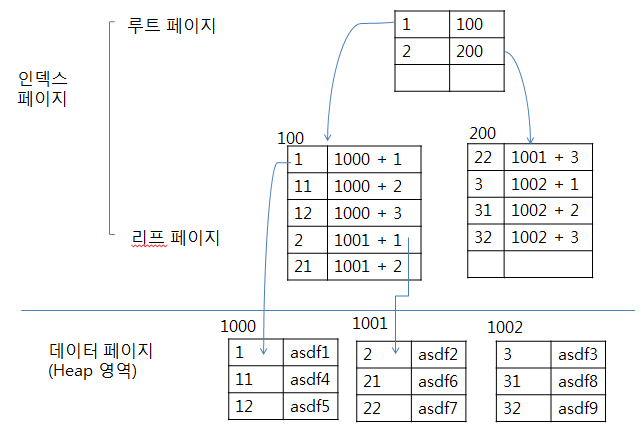
아래 그림은 Nonclustered Index + Clustered Index 그림이다.

'CS > DB' 카테고리의 다른 글
[Database] - Hash index / B-Tree index (0) 2022.10.06 [Database] - Index (1) 2022.10.03 Data Lake / Warehouse / Mart (0) 2022.09.19 [MSSQL] 특정 기간 날짜 (MASTER.DBO.SPT_VALUES) (0) 2022.03.21 INDEX 조각화( Rebuild , Reorganize ) (0) 2022.03.04